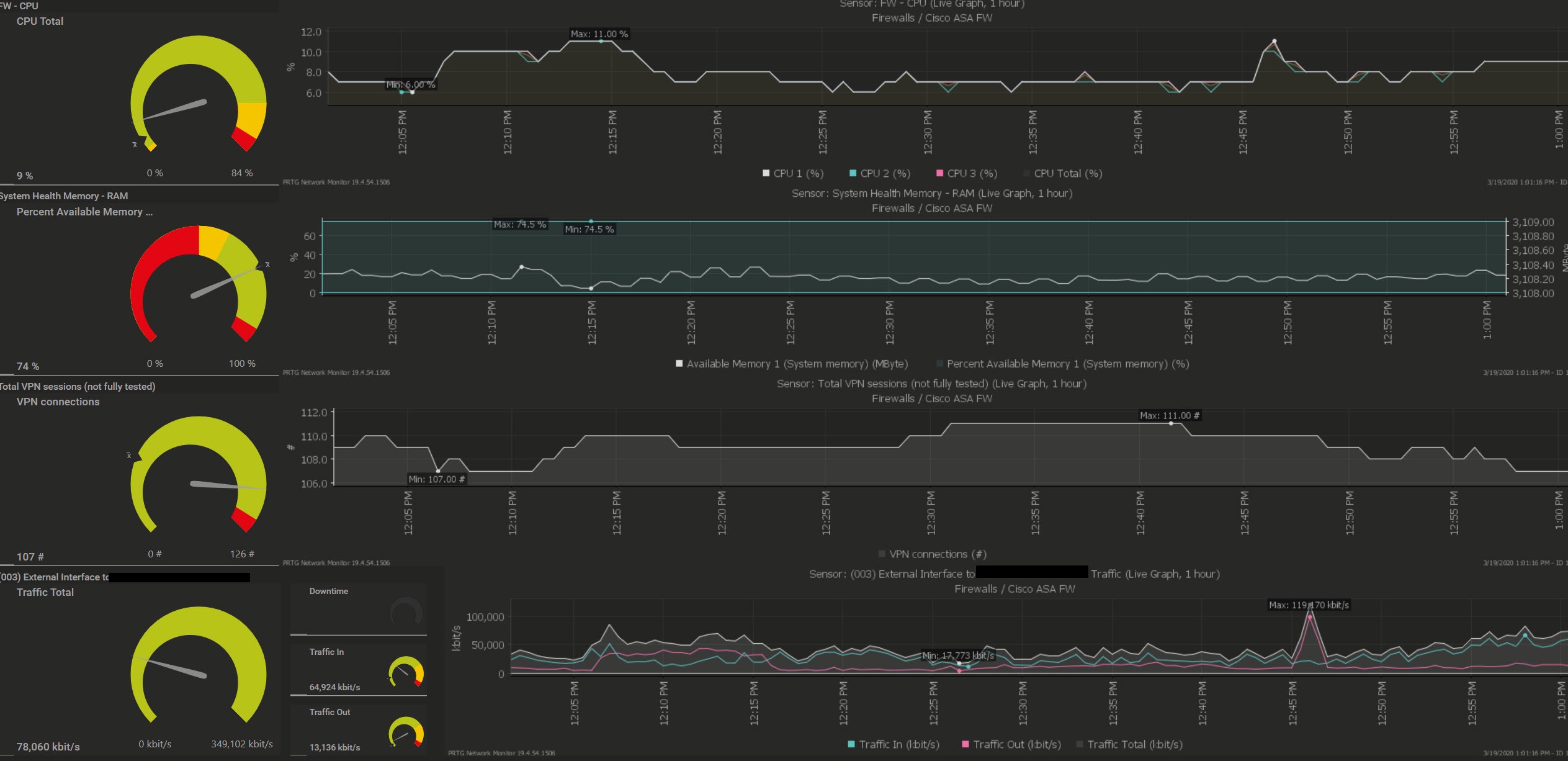
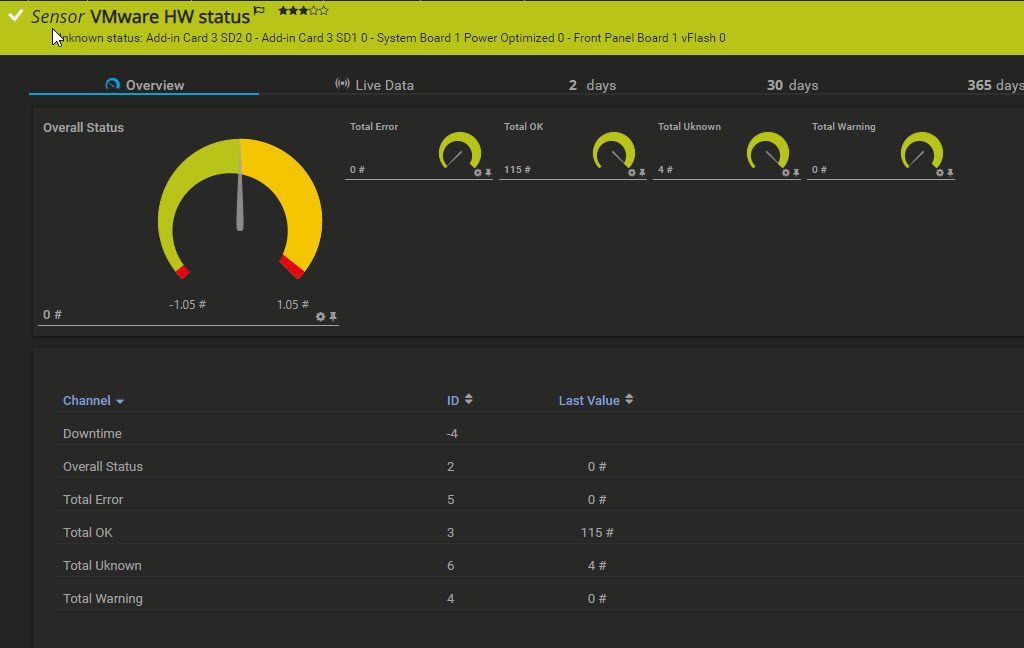
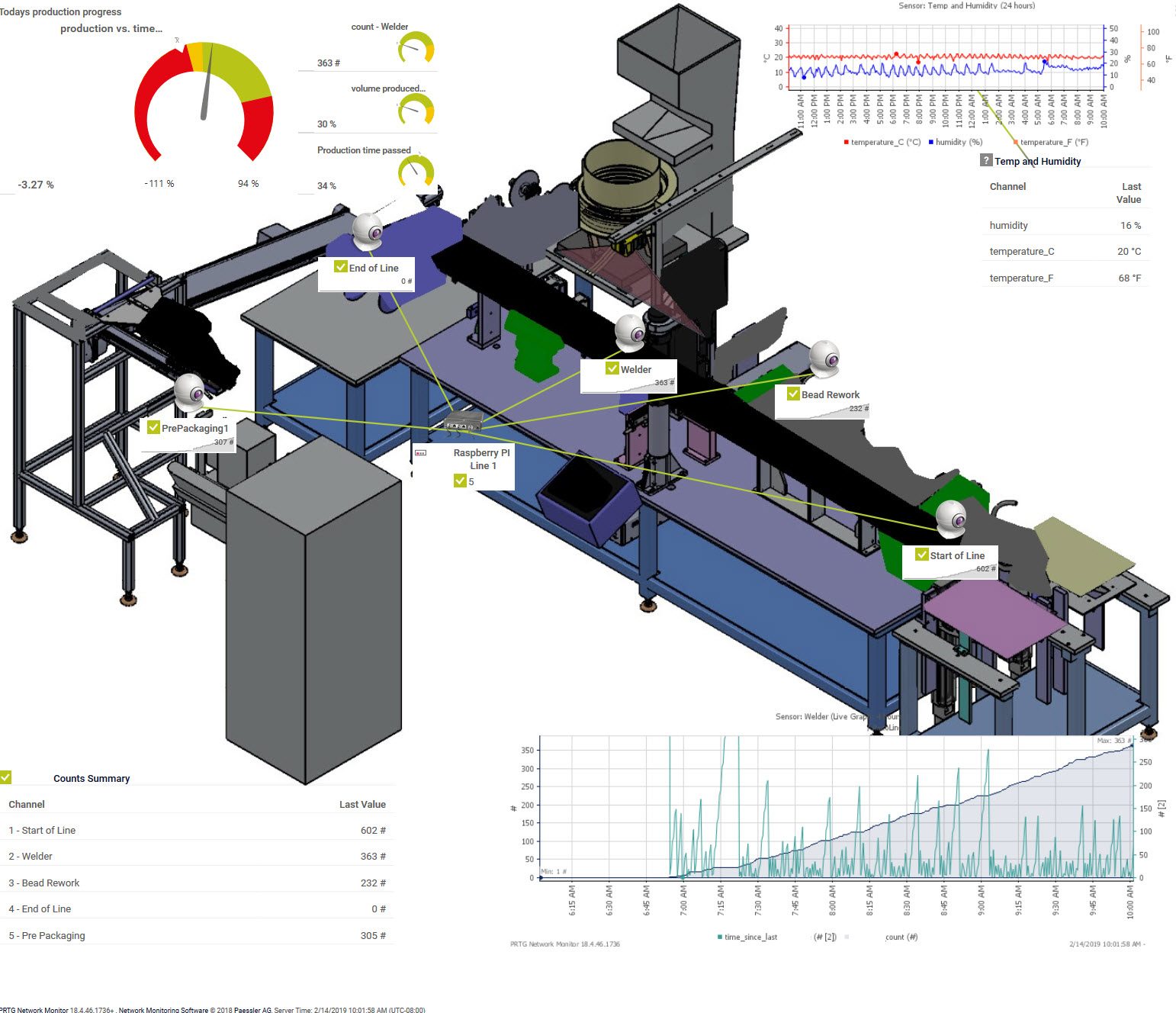
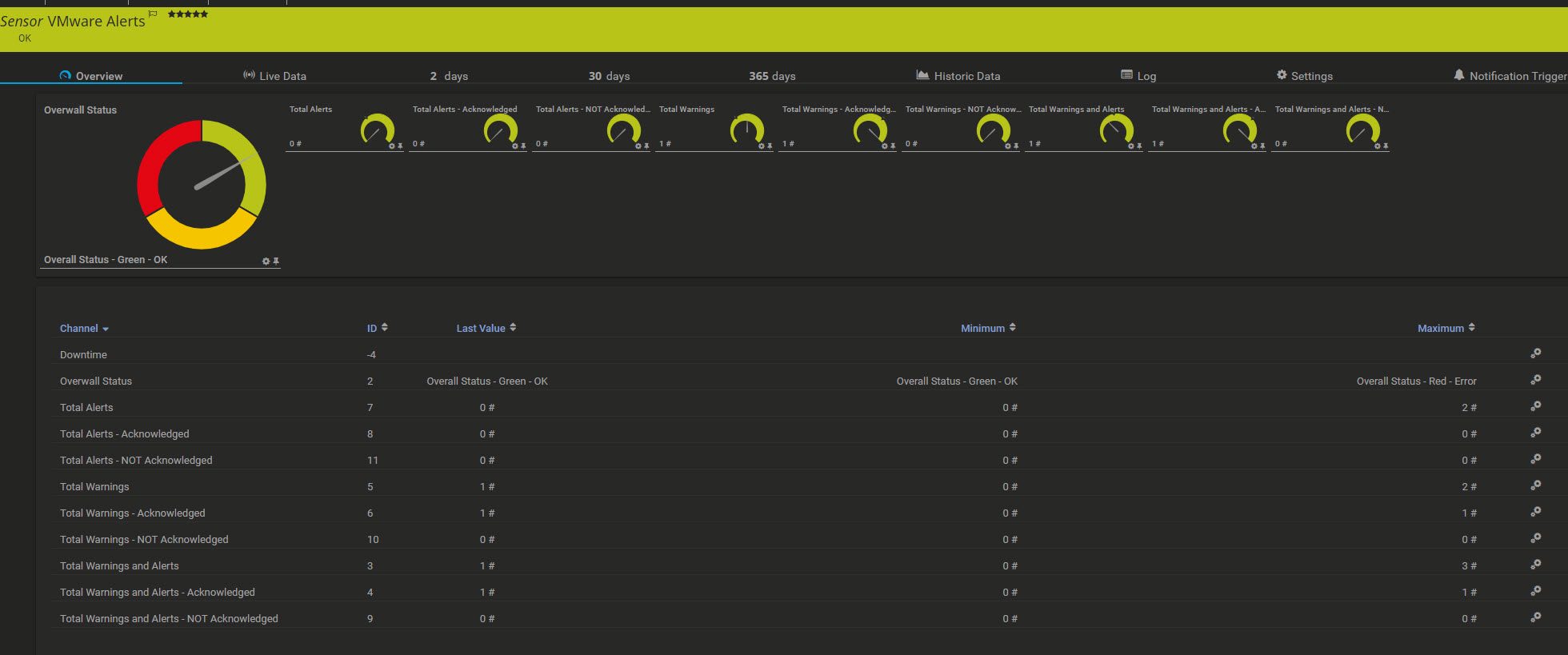
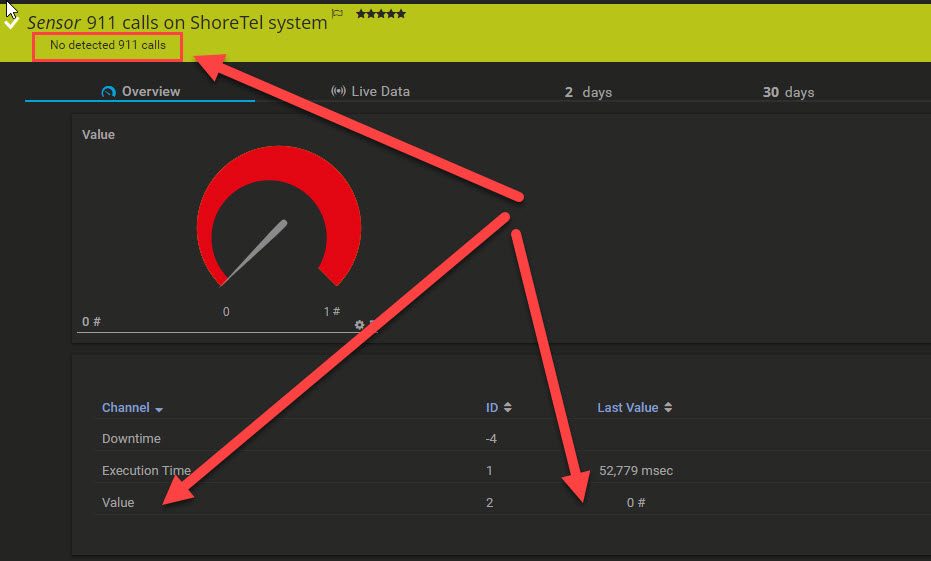
The following script will monitor a specific directory for a file of a defined type and minimum size, it will report back to you the newest file of the specified type and over the minimum size and provide you the file age and size to PRTG.
The name of the file will also be reported back as a text value for the sensor in PRTG.
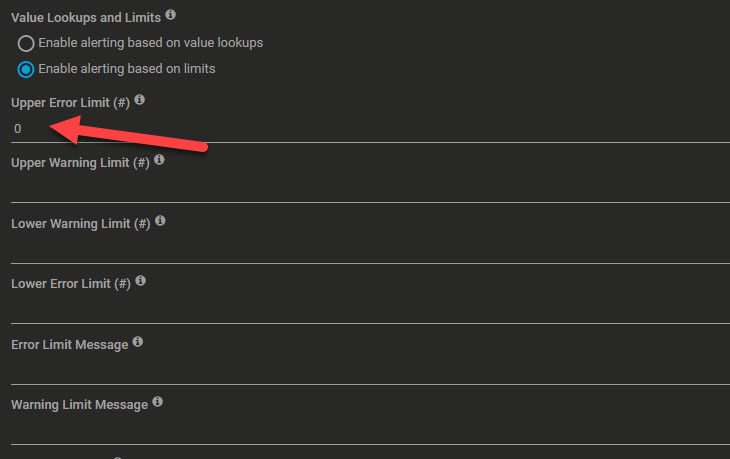
If the script encounters any errors, the total files value will be 0 for no files found or -1 for a script error. Therefor please set minimum channel error values accordingly to get alerted.
The goal here is to get the age of the file back that was found, to make sure the file is not older than expected. This is needed for some automated exports or data transfer files, this was you can be sure that your export routines work as expected.
param(
[string] $FolderPath = "C:\",
[string] $Extension = "*.undefined",
[int] $FileMinimumSizeByte = 1
)
Function WriteXmlToScreen ([xml]$xml)
{
$StringWriter = New-Object System.IO.StringWriter;
$XmlWriter = New-Object System.Xml.XmlTextWriter $StringWriter;
$XmlWriter.Formatting = "indented";
$xml.WriteTo($XmlWriter);
$XmlWriter.Flush();
$StringWriter.Flush();
Write-Output $StringWriter.ToString();
}
Try {
$Files = Get-ChildItem -Path $FolderPath -Filter $Extension | Where {$_.Lengthength -gt $FileMinimumSizeByte} | Sort-Object CreationTime -Descending
If ($Files.Count -gt 0) {
Foreach ($File in $Files)
{
$TotalFiles = $Files.Count
$Date = Get-Date
$FileAgeSeconds = [math]::Round(($Date - $File.CreationTime).TotalSeconds)
$FileSize = $File.Length
$FileName = $File.Name
$XML = "<prtg>"
$XML += "<result><channel>Total Files</channel><value>$TotalFiles</value><unit>Count</unit></result>"
$XML += "<result><channel>Newest File - Age in Seconds</channel><value>$FileAgeHours</value><unit>TimeSeconds</unit></result>"
$XML += "<result><channel>Newest File - Size in Bytes</channel><value>$FileSize</value><unit>Byte</unit></result>"
$XML += "<text>$FileName</text>"
$XML += "</prtg>"
WriteXmlToScreen $XML
Break;
}
} else {
$XML = "<prtg>"
$XML += "<result><channel>Total Files</channel><value>0</value><unit>Count</unit></result>"
$XML += "<result><channel>Newest File - Age in Seconds</channel><value>0</value><unit>Count</unit></result>"
$XML += "<result><channel>Newest File - Size in Bytes</channel><value>0</value><unit>Byte</unit></result>"
$XML += "<text>No Files found</text>"
$XML += "</prtg>"
WriteXmlToScreen $XML
}
} Catch {
$XML = "<prtg>"
$XML += "<result><channel>Total Files</channel><value>-1</value><unit>Count</unit></result>"
$XML += "<result><channel>Newest File - Age in Seconds</channel><value>-1</value><unit>Count</unit></result>"
$XML += "<result><channel>Newest File - Size in Bytes</channel><value>-1</value><unit>Byte</unit></result>"
$XML += "<text>Error</text>"
$XML += "</prtg>"
WriteXmlToScreen $XML
}