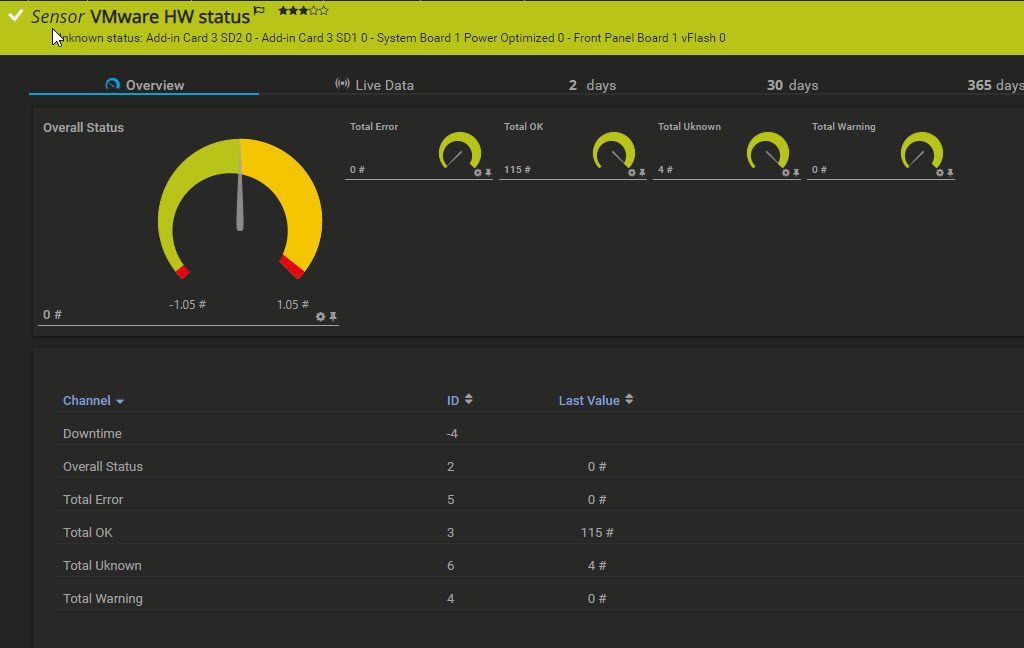
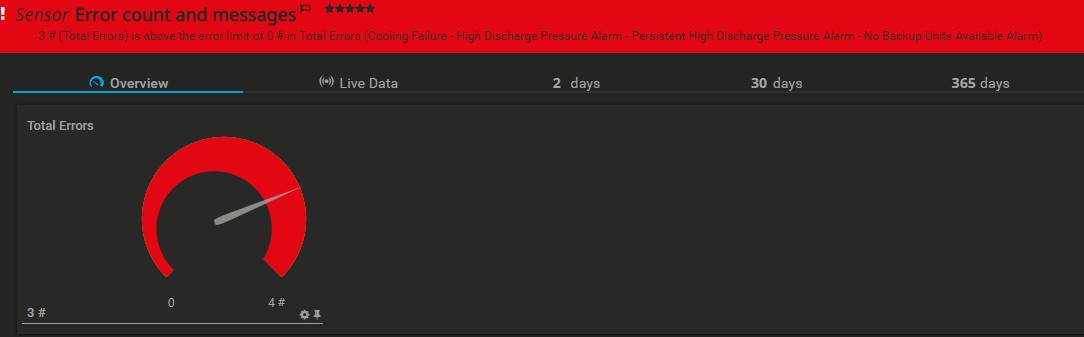
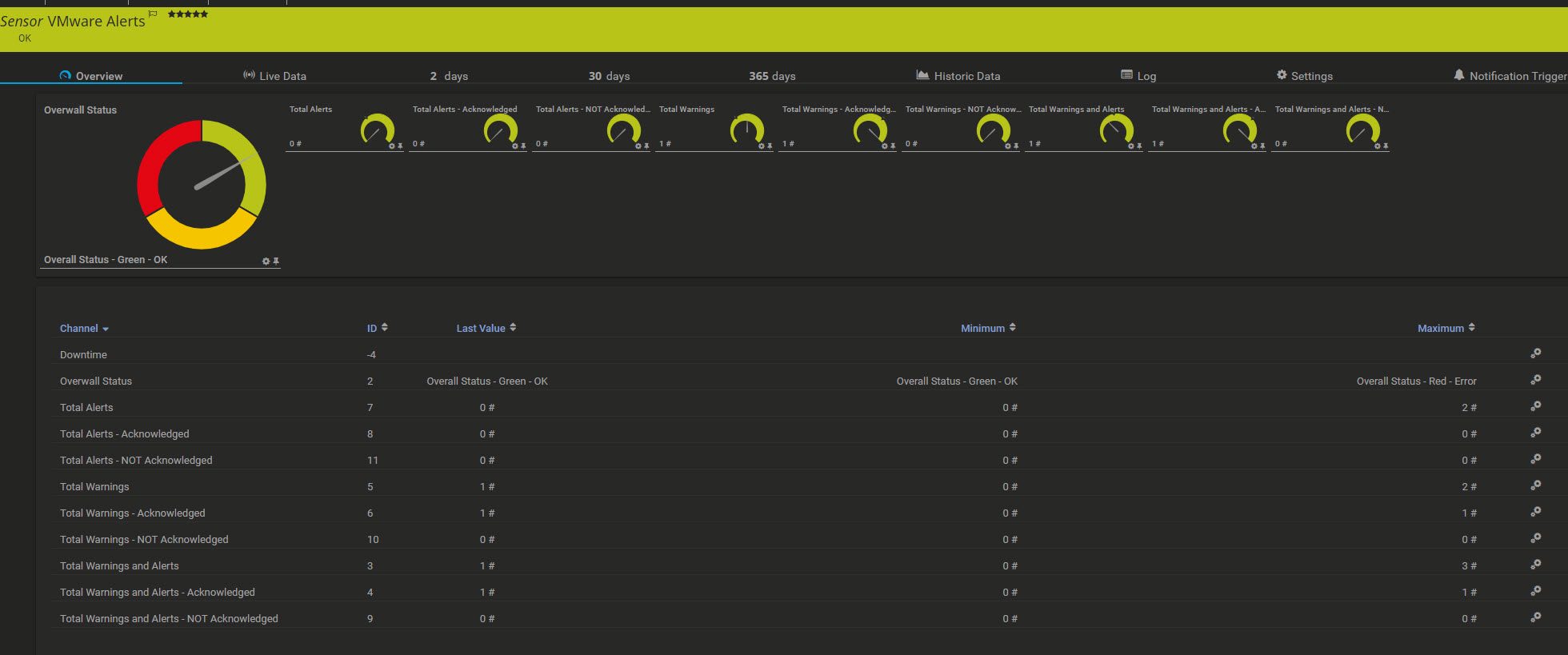
Clear
$NewRootPath = "$env:USERPROFILE\OneDrive - MYDOMAIN\User Profile"
$regUSF = "HKCU:\Software\Microsoft\Windows\CurrentVersion\Explorer\User Shell Folders"
$regSF = "HKCU:\Software\Microsoft\Windows\CurrentVersion\Explorer\Shell Folders"
$Folders = "Personal,My Pictures,My Music,My Video,Favorites,Desktop"
$Folders = $Folders.Split(",")
$FolderNames = "Documents,Pictures,Music,Videos,Favorites,Desktop"
$FolderNames = $FolderNames.Split(",")
$AddSize = 2000000000 #free space in Bytes to add if files are on a different volume (2000000000 = about 2 GB)
$ArrayPosition = -1
Function Move-KnownFolderPath {
Param (
[Parameter(Mandatory = $true)]
[ValidateSet('Desktop', 'Documents', 'Downloads', 'Favorites', 'Music', 'Pictures', 'Videos')]
[string]$KnownFolder,
[Parameter(Mandatory = $true)]
[string]$Path
)
# Known Folder GUIDs
$KnownFolders = @{
'Desktop' = @('B4BFCC3A-DB2C-424C-B029-7FE99A87C641');
'Documents' = @('FDD39AD0-238F-46AF-ADB4-6C85480369C7','f42ee2d3-909f-4907-8871-4c22fc0bf756');
'Downloads' = @('374DE290-123F-4565-9164-39C4925E467B','7d83ee9b-2244-4e70-b1f5-5393042af1e4'); #not in use - just in case you want to use it..
'Favorites' = '1777F761-68AD-4D8A-87BD-30B759FA33DD';
'Music' = @('4BD8D571-6D19-48D3-BE97-422220080E43','a0c69a99-21c8-4671-8703-7934162fcf1d');
'Pictures' = @('33E28130-4E1E-4676-835A-98395C3BC3BB','0ddd015d-b06c-45d5-8c4c-f59713854639');
'Videos' = @('18989B1D-99B5-455B-841C-AB7C74E4DDFC','35286a68-3c57-41a1-bbb1-0eae73d76c95');
}
$FolderGUID = ([System.Management.Automation.PSTypeName]'KnownFolders').Type
#create the Type entry if it does not yet exist / relates to the Registry eventually
If (-not $FolderGUID) {
$KnownFolderGUID = @'
[DllImport("shell32.dll")]
public extern static int SHSetKnownFolderPath(ref Guid folderId, uint flags, IntPtr token, [MarshalAs(UnmanagedType.LPWStr)] string path);
'@
$FolderGUID = Add-Type -MemberDefinition $KnownFolderGUID -Name 'KnownFolders' -Namespace 'SHSetKnownFolderPath' -PassThru
}
If(!(Test-Path $Path)){
#in case folder does yet exist, we create it
Try {
New-Item -Path $Path -Type Directory -Force -ErrorAction SilentlyContinue
} Catch {}
}
#set the new folder path
ForEach ($TmpGUID in $KnownFolders[$KnownFolder]) {
$tmp = $FolderGUID::SHSetKnownFolderPath([ref]$TmpGUID, 0, 0, $Path)
}
Attrib +r $Path #needed to retain the icon
}
ForEach ($Folder In $Folders)
{
$ArrayPosition += 1
Write-Host "Working on folder"$FolderNames[$ArrayPosition] -BackgroundColor DarkGreen
$SourcePath = (Get-ItemProperty -Path $regUSF -Name $Folder).$Folder
If ($SourcePath.Length -gt 0)
{
Write-Host "..checking source path: $SourcePath"
If ((Test-Path -Path $SourcePath)){
Write-Host "....path is accessible"
$CompSource = Get-Item -Path $SourcePath
$CompareResult = $false
If ((Test-Path -Path ($NewRootPath + "\" + $CompSource.Name))){
$CompTarget = Get-Item -Path ($NewRootPath + "\" + $CompSource.Name)
Write-Host "..Comparing Source Path: "$CompSource.FullName
Write-Host "....with Target Path: "$CompTarget.FullName
If ($CompSource.FullName.ToLower() -eq $CompTarget.FullName.ToLower()){
$CompareResult = $true
} Else {
$CompareResult = $false
}
} Else {
Write-Host "..Target Path does not exist"
}
If ($CompareResult -eq $true){
Write-Host "..Source and Target path are identical: $CompTarget" -ForegroundColor Yellow
Write-Host "....Not applying any changes!" -ForegroundColor Yellow
Pause
} Else {
$SourceFolder = Get-Item -Path $SourcePath
Write-Host "..accessing source folder $SourceFolder" -ForegroundColor Green
If (!(Test-Path -Path ($NewRootPath + '\' + $SourceFolder.Name))){
Move-KnownFolderPath -KnownFolder ("" + $FolderNames[$ArrayPosition] + "") -Path ($NewRootPath + '\' + $FolderNames[$ArrayPosition])
$TargetPath = Get-Item -Path ("$NewRootPath\" + $FolderNames[$ArrayPosition])
Write-Host "..created new folder $TargetPath"
#compare source size with target free space here
Write-Host "..Comparing Source and Target drive letters"
If ($NewRootPath.SubString(0,2).ToLower() -ne $SourcePath.SubString(0,2).ToLower())
{
#source drives are different.. we need to obey the SourceSize against the free space on the target
Write-Host "....Source and Target drive letters are different"
Write-Host "......Please wait while calculating the source size"
$SourceSize = (Get-ChildItem -Path $SourcePath -Recurse | Measure-Object -Property Length -Sum -ErrorAction SilentlyContinue).Sum
$TargetFree = Get-PSDrive $NewRootPath.SubString(0,1) | Select-Object Free
If ($SourceSize -gt $TargetFree.Free) {
Write-Host "......The Source size of $SourceSize Bytes is bigger then the free space on the Target of $TargetFree.Free Bytes" -ForegroundColor Red
} ElseIf (($SourceSize + $AddSize) -gt $TargetFree.Free) {
Write-Host "......The Source size of $SourceSize Bytes is close to the free space on the Target of $TargetFree.Free Bytes" -ForegroundColor Yellow
} Else {
Write-Host "......The Source size of $TargetFree.Free Bytes is sufficient to hold the data from the Source of $SourceSize Bytes" -ForegroundColor Green
}
Pause
} Else {
Write-Host "....Source and Targets are on the same drive, all good"
}
Write-Host "..Moving data from: $SourcePath"
Write-Host "....to folder: $TargetPath"
Write-Host "....This can take several minutes..."
Move-Item -Path ("" + $SourcePath + "\*") -Destination $TargetPath -Force -ErrorAction SilentlyContinue
Write-Host "....Done moving data"
} Else {
Write-Host "..Warning - Target Path exists already: $CompTarget" -ForegroundColor Yellow
Write-Host "....Files will not be moved, registry still will be adjusted to the target path!" -ForegroundColor Yellow
Pause
Move-KnownFolderPath -KnownFolder ("" + $FolderNames[$ArrayPosition] + "") -Path ($NewRootPath + '\' + $FolderNames[$ArrayPosition])
Write-Host "....Finished adjusting registry"
}
Write-Host "..Trying to remove $SourcePath"
Pause
Try {
Attrib -r -s $SourceFolder.FullName
Remove-Item -Path $SourceFolder.FullName -Force -Confirm:$false -Recurse -ErrorAction SilentlyContinue
} Catch {}
Try {
Attrib -r -s ($SourceFolder + "\desktop.ini")
Remove-Item -Path ($SourceFolder + "\desktop.ini") -Force -Confirm:$false -ErrorAction SilentlyContinue
} Catch {}
Try {
Rename-Item -Path $SourceFolder -NewName ($SourceFolder.Name + ".old") -Force -ErrorAction SilentlyContinue
} Catch {}
}
} Else {
Write-Host "....SourceFolder Path invalid: $SourcePath" -ForegroundColor Red
}
}
Write-Host "..Done processing"$FolderNames[$ArrayPosition] -BackgroundColor Blue
Pause
}
Write-Host "Script finished processing" -ForegroundColor Green
Pause